
I have written some posts on the importance of parallel execution and how to program parallel integration workflows with my Integration Tag Language. A workflow called a <schedule> often consists of a number of workflow steps called <job>. Here is a ‘bare bone’ schedule with 2 jobs processing a file with 100 rows:

When this schedule executes these jobs execute one by one in sequence. If the jobs are independent of each other it would be better to execute them in parallel, this is achieved by adding the parallel attribute to the jobs, like this:
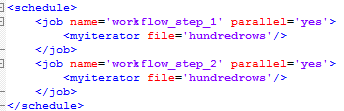
If job 1 takes 1 minute and job 2 takes 10 minutes then you have not gained much by parallel process the two jobs, the jobs are unbalanced from a parallelization view. If we break down job two into 10 parallel sub processes the 2 jobs are balanced. You do this by introduce a job iterator and piggyback connect the myiterator to the jobiterator, like this:

Here the jobiterator cuts the file into 10 pieces and parallel execute them all, each chunk is given to a myiterator. In theory the two jobs should now execute in 1 minute and this is what I refer to as parallel balanced workflow. The wall clock time is reduced by 82%, with very little effort.
In real life not many workflows behaves as nicely as this one, you may have to adjust the chunks a bit to achieve about equal execution time.
No comments:
Post a Comment