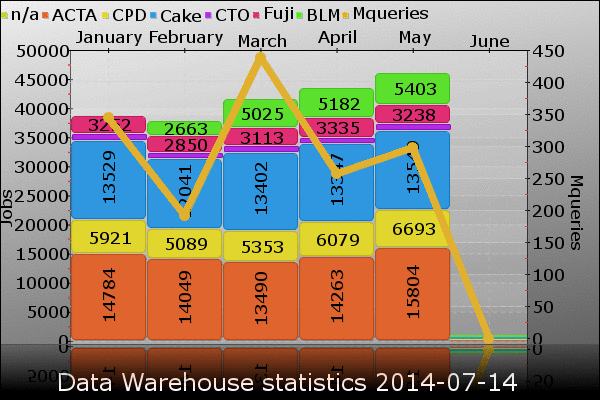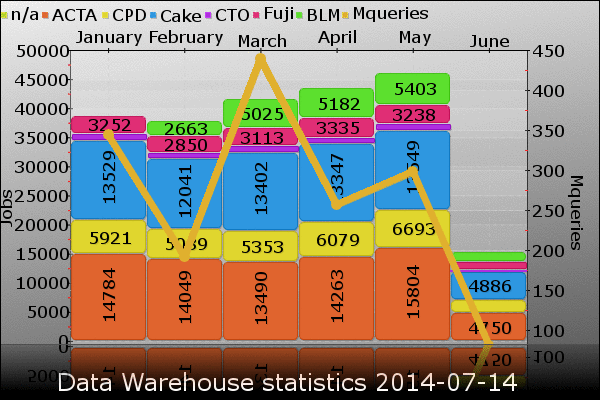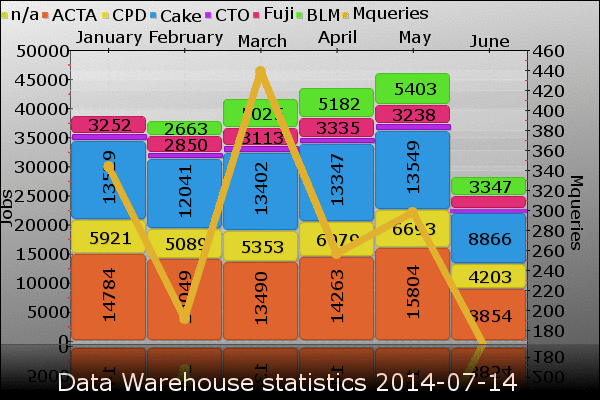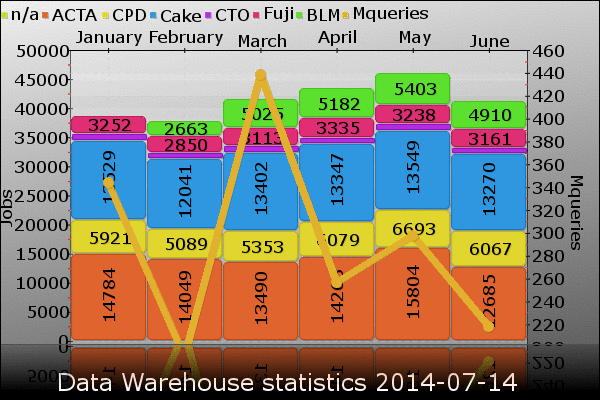
I recently read a post how to search engine optimize blog posts. I decided to look for my own posts in Google to find out how well my posts were doing in Googles search engine. To my pleasure I found my posts showed up, some even quite high, when I searched for them. But I was a bit saddened to find extracting data from SAP was hard to find, a year ago it was ranked higher but I suppose many posts is written about this subject. (Still I find my post informative, with a practical hands on examples.) By prefixing my search term with 12d (the name of my blog) all my posts I tried showed up, except some data warehouse, no matter how I tried to find it, the post refused to show up in the search result. Other posts of mine showed up, while explicitly searching for some data warehouse but not the post itself. I have checked the post, and I cannot find a reason in the post for not showing up in the search result. The quality is no worse than most of my other posts. No broken links. No explicit language, no controversial anything. It is a mystery to me why the some data warehouse post refuse to show up in the search result.
(Update! I just had to put double quotes around the argument to find my post. There are a lot of "some" + "data" + "warehouse", that is probably the reason why I could not find my post. However the meaning of "some" is different, in the other posts "some" means "unspecified number". I use "some" as in "some chicken", "some data warehouse".)
(Update! I just had to put double quotes around the argument to find my post. There are a lot of "some" + "data" + "warehouse", that is probably the reason why I could not find my post. However the meaning of "some" is different, in the other posts "some" means "unspecified number". I use "some" as in "some chicken", "some data warehouse".)
While searching for my own posts I checked how many have read my posts, and the now not so easy to find extracting data from sap was a clear winner with 736 pageviews, with replicating MySQL with Rsync as the runner up 652 pageviews. Not bad at all, even if many readers was not what I had in mind when I started blogging, it is very rewarding you people out there read my posts. Actually I’m mesmerized by the view stats looking at it almost every day. What I think is a bit sad not more than 30 have read my posts on relational big data, I think they are good and worth some minutes of your time. But what is really think is a pity no more than 14 have read php parallel job scheduling 4. This post shows how to parallel process and rightsize business processes like extraction of data from source systems, a complex and advanced post from a different viewpoint from most writings about parallel processing, which typically deals with speeding up the minute atomic parts of computer programs. The entire serie of parallel workflow processing is worth reading, but I suppose very few are interested in this topic, especially when parallel is done in PHP, so 14 pageviews is maybe not that bad:-)