This was supposed to be a rather lengthy post, but zscaler was tired today, making me waiting for gateway.zscaler.net for to long, and now time is running out but...
Another year have past again. At work I didn’t accomplish at all what I had hoped for. But I have done some other things, like helping out with evaluating software and some integration problems. I did not do one line of JavaScript coding which I really had hoped to do, this is only partly due to lack of time I hadn’t any good projects for javaScript and I do not code just for the sake of coding. I didn’t buy a raspberry Pi same thing there I didn’t have a good project for a raspberry Pi. I didn’t try Perl6. There are a lot of things I didn’t do. But I tested the Amazon infrastructure learned a few thing about Azure cloud. I managed to create a travel expense report by myself, I never done that before so I’m happy for that.
Two colleagues have left this year, that is never fun. A data warehouse specialist left and that was not only un-fun it was almost painful, I’m still emotionally attached to my old data warehouse and those who work there.
Actually the zscaler just went bananas, it blocked my internet access with this prompt
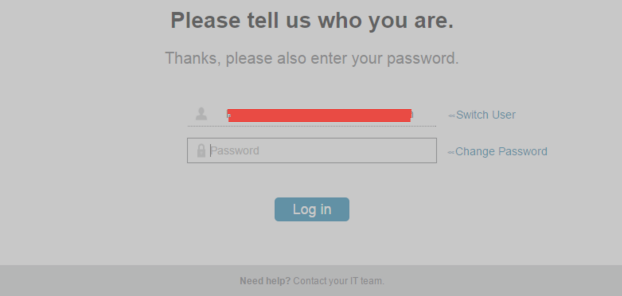
I would never type in a password in a frame like this. Need help contact your IT team, this is the 31 of december at 16:45 do not think anyone will answer.
Years end is the most IT-important day of the year, and you should make an extra effort to avoid anything that can interrupt or disrupt IT services this and next day of the year.