<?php
/**
* A PDO executor - dynamically included in {@link execScript()}
*
* This code is intended for communication with external database managers via PHP Database Object layer.
* The primary purpose is to copy data from the external DBMS into our own DBMS (Mysql).
*
* Example, Copy 'schedule' table/wiew from external DBMS 'DB2', to our database 'test':
*
* <job name='ajob' type='script' data='pdo.php'> <br>
* <pdo> <!-- pdo syntax follows <script><sql> --> <br>
<dsn>ibm_db2</dsn> <!-- dsn pointing to DBMS), specified in custom/pdo.xml --> <br>
* <sql>select * from DB.schedule;</sql> <br>
* <sqlconverter> <br>
* <name>pdoconverter_loadfile01.php</name> <br>
* <target>copy0</target> <br>
* <autoload>replace</autoload><database>test</database><truncate>yes</truncate><table>schedule</table> <br>
</sqlconverter> <br>
* </pdo> <br>
*
* <script> <br>
* <sql><file>copy0.SQL</file></sql> <br>
* </script> <br>
* </job> <br>
*
* The <dsn> xml tag, points to a named entry in custom/pdo.xml. You can specify a default dsn in
* the context.
* You specify a <pdo></pdo> block for communication with the external DBMS, and an
* optional <script></script> block for communication with the native mysql DBMS.
*
* You are not restricted to this example, You can do about anything inside the <pdo> tag you can do
* inside a sql <script> tag, given the restrictions the pdo DBMS driver implies.
* Note! you can write your own import sql inside the <script>, you are not restricted to the
* {@link pdoconverter_loadfile01.php autoload} facility.
*
* Processing:
* 1 connect to the external database manager by sending the <pdo> block to {@link execPdo()}
* 2 connect to internal dbms by sending the <script> block to {@link execSql()}
* @author Lasse Johansson <lars.a.johansson@se.atlascopco.com>
* @package adac
* @subpackage utillity
* @return bool $_RETURN This is what the calling execSchedule checks at return not the returned boolean
*/
file_put_contents('mydriver',
serialize(array(0 =>array(
'scheduleid'=>$schedule['_scheduleid'],
'jobid' =>$job['_jobid'],
'odbcmsg' =>'A serious error has occured, contact your baker'))));
$rows = array();
$zlogsql = $job['loginit'][0]['value'];
$logsqls = explode("\n",$zlogsql);
foreach($logsqls as &$logsql){$logsql = trim($logsql," ;\t\n\r");}
$logsql = implode(' ',$logsqls);
// print_r($logsql);
$mysql_cake = connect2mysql($context);
$OK = execQuery ($mysql_cake, $logsql, $rows);
if(!$OK) return FALSE;
$mysql_cake->close();
$stmts = FALSE;
$queries = array();
// if (array_key_exists('_sqlarray', $job)) $stmts = $job['_sqlarray'];
if (!$stmts and array_key_exists('script', $job)) {
if (array_key_exists('sql', $job['script'])) $stmts=$job['script']['sql'];
}
if(!$stmts and array_key_exists('sql', $job)) $stmts = $job['sql'];
if ($stmts == FALSE) return FALSE;
print_r($queries);
foreach($stmts as $key => $stmt){
$queries = array_merge($queries, parseSSV($stmt['value']));
}
foreach($queries as &$query){$query = trim($query," ;\t\n\r");}
print_r($queries);
$sqllog = new log("logfile=ODBClog.txt onscreen=no mode=all");
$log->logit('Note',"Environment and input directory are OK, commencing SQL process, details see ODBClog.txt");
$sqllog->logit('Note',"Here we go...");
// return $queries;
$hostSys = 'winodbc';
$odbcParm = getSysContactInfo($context,$schedule,$job,$hostSys);
print_r($odbcParm);
$odbcName = $odbcParm['name'];
if ($odbc = odbc_connect( $odbcName,$odbcParm['user'],$odbcParm['passwd'])) {
$log->logit('Info',"Could connect to odbc driver $odbcName");
}
else {
$odbcmsg = odbc_error();
$odbcmsg = "ODBC Driver Connection login timed out., SQL state " . $odbcmsg;
$log->logit('Failed',"Could not connect to odbc driver " . $odbcName);
$log->logit('Failed', $odbcmsg);
$sqllog->logit('Note',$odbcmsg);
file_put_contents('mydriver',
serialize(array(0 =>array(
'scheduleid'=>$schedule['_scheduleid'],
'jobid' =>$job['_jobid'],
'odbcmsg' =>$odbcmsg))));
return FALSE;
}
$returncodes = array();
for($i= 0; $i < count($queries); $i++) {
$Xquery = $queries[$i];
// print "$i $Xquery\n";
$odbcmsg = 'OK, no problems';
if (!$result = odbc_exec($odbc, $Xquery, 1)){
if(odbc_error()== 'S1090'){
$odbcmsg = 'OK, No data to FETCH, S1090';
$sqllog->logit('Note',"$odbcmsg ");
$log->logit('Note',"$odbcmsg ");
}else {
$odbcmsg = odbc_errormsg($odbc);
$sqllog->logit('Failed',"$odbcmsg ");
$log->logit('Failed',"$odbcmsg ");
return FALSE;
}
}
if($result){
if(! odbc_num_fields($result)) continue;
$sqlconverterDir = $context['sqlconverter'];
$sqlconverter = $job['sqlconverter'][0]['name'][0]['value'];
if($sqlconverter == '') $sqlconverter= 'sqlconverter_odbcdefault.php';
$sqltarget = $job['sqlconverter'][0]['target'][0]['value'];
if ($sqltarget == '') $sqltarget='driver0';
$sqllog->logit('Note',"Loading sqlconverter=$dir$sqlconverter");
/**
* This includes an SQL result set converter. <br>
* The converter is specified in the job and included from the SQLconverter library.<br>
* The converter uses $odbc handle and stores the result in $sqltarget.<br>
* See {@link sqlconverter_default.php The default SQL result converter} for details.
*/
include("$sqlconverterDir"."$sqlconverter");
// $result= close();
}
}
$odbc = odbc_close($odbc);
file_put_contents('mydriver',
serialize(array(0 =>array(
'scheduleid'=>$schedule['_scheduleid'],
'jobid' =>$job['_jobid'],
'odbcmsg' =>$odbcmsg))));
$zlogsql = $job['logfetch'][0]['value'];
$logsqls = explode("\n",$zlogsql);
foreach($logsqls as &$logsql){$logsql = trim($logsql," ;\t\n\r");}
$logsql = implode(' ',$logsqls);
// print_r($logsql);
$rows = array();
$mysql_cake = connect2mysql($context);
$OK = execQuery ($mysql_cake, $logsql, $rows);
if(!$OK) return FALSE;
$mysql_cake->close();
$_RESULT = TRUE;
return TRUE;
|


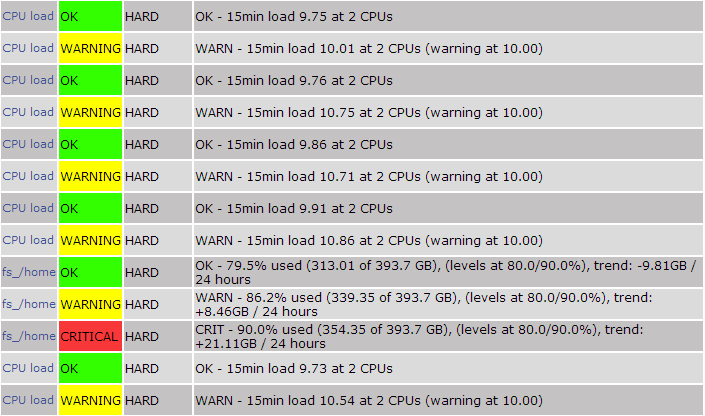










 This example still takes 22 seconds to run, but we do not have to take care of the result, we got it automagically in a nice database table.
This example still takes 22 seconds to run, but we do not have to take care of the result, we got it automagically in a nice database table.




 And this is what this example does. This is a very advanced example which is worth study in detail, this parallel example follows the
And this is what this example does. This is a very advanced example which is worth study in detail, this parallel example follows the

