Stockholm 2016-01-17
Recently I looked into some Data Warehouse systems. And I learned there is not anything on the market that compares with my Data Warehouse, I would not say my is better but it is very different from the others. Personally I’m convinced my Data Warehouse concept is better, but that is what we all creators of Data Warehouses say I suppose.
Most Data Warehouse architectures are based on multidimensional cubes with a fact table in the middle. This model was conceived in the late seventies when the capabilities of the infrastructure were much weaker than today. Cubes have some intrinsic merits they give a logical structure to the data, have low redundancy and are economical with disk space. But there are disadvantages of cubes which outweighs the strengths. Cubes are hard to understand and decode. Very few non-specialists can extract data directly from cubes. Cubes are complex to maintain, and they are slow to access. I prefer simple two dimensional tables containing all data needed for a report. Tables are simple to understand and easily accessible from spreadsheets which are in every business user's toolbox. Data in my warehouse is organised in tables not in cubes.
Most data warehouses store data in relational databases which are accessed and manipulated via SQL statements. For some reason most Data Warehouse system goes to great lengths to conceal SQL from the Data Warehouse admins, instead they invent their own access language or extend a common programming language with their own access libraries. I created a workflow engine and scheduler which focus on executing jobs with a minimum of ‘macro code’, data manipulation is done directly by SQL. The entire ETL process is written in SQL, instead of an obscure language only insiders understand.
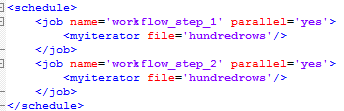
ETL processes of Data Warehouses often process very large amounts of data, parallel process workflows and split workflows into parallel ‘subflows’ is of paramount importance. My implementation of parallelism via piggyback iterators, is the simplest and most elegant parallel programing algorithm I’m aware of and it is a far cry from other traditional parallel programing idioms.
My Data Warehouse: Two dimensional tables, SQL and simple sound parallelism.