
Another year has passed, a new is to come.
For me 2013 was a busy year, I moved to Corporate IT as Lead Information Architect. In a way I’m back where I started forty years ago, at the Corporate IT department. At this time last year I had planned my Calendar for 2013, with the new job I had to change my plans. Last year I was very involved in Atlas Copco Industrial Technique’s Business Intelligence system. My job was operational and I had to plan accordingly. Now my job is more strategic and I have to plan for that. More meetings, less ‘real’ job. I had forgot, meetings are very hard work. One or two 1 hour long meetings a day is ok, but participate in telcos the entire day keeping focus is exhausting, I’m tired at the end of the day, just to start all over the next day. But I do not complain my problems are very much luxury problems, lot’s of hard work. It is still hard times and many wish they had my problems.
Last year I thought, 2013 would be a year of Business Intelligence and I was right, I have done and still do to a certain extent work with BI, but to that I added IT-architecture and Master Data Management.
One Business Area within Atlas Copco, Mining and Rock Excavation Technique, has started a master data management project, next year I will join this project and try to help making this system global for all Atlas Copco.
Next year I hope to work with Business Intelligence on group level. First I need to understand all different BI initiatives and systems in Atlas Copco since there is little coordinated activities in this areas today. There are strategies and policies in place for the Atlas Copco Group, but this is nothing I will write about until I have a better understanding of them and I know where we stand.
I have failed to make people in the business realise how much Master Data Management can benefit from Business Intelligence, I will do my best to convince my colleagues next year. This is something I feel strongly for and it combines my two most important missions BI and MDM for next year. As an IT-architect I will participate in work with Data Design Authority and reference architecture for Master Data Management.
On a more personal level I will finally start learn Javascript and Node.js. I already have started to build web services, all this is new to me, I been mucking around with some web programming before but nothing serious. Then I hope to start up either Perl6 or D programming, both languages interests me a lot. I’ve muck around a bit with these languages but nothing serious.
I’m overly optimistic of what I can achieve in future and the plans for next year is no exception. Simple things planned often shows to be complicated, and more complex things planned shows to be very hard, it is seldom the other way around. New high prioritized tasks will show up.
My new year promise for 2014.
I will cut down blogging. I write far to many blog posts. I aim for twenty posts next year. But I use this blog partly for documenting so it’s a bit dependent on how much I do which I consider worth a document.

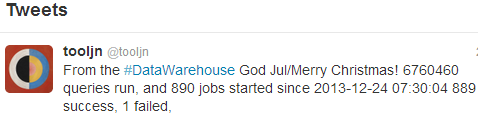


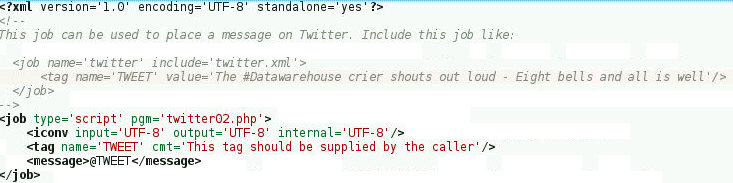



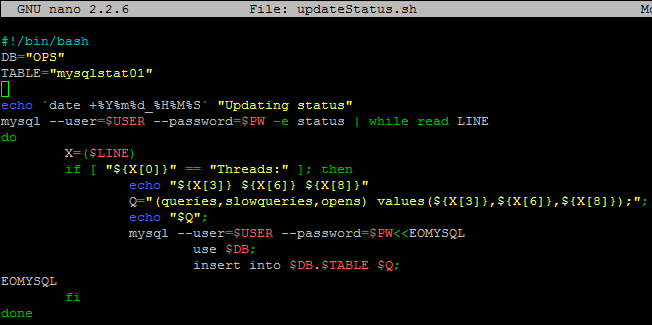

{kind=link}